- 技术(专利)类型 发明专利
- 申请号/专利号 201510881758.5
- 技术(专利)名称 分布式数据库中并发工作负载的性能预测方法
- 项目单位
- 发明人 李晖 陈梅
- 行业类别 人类生活必需品
- 技术成熟度 详情咨询
- 交易价格 ¥面议
- 联系人 李先生
- 发布时间 2021-03-10
 北京
北京
客服热线:010-83278899
 微信公众号 扫一扫 关注我们
微信公众号 扫一扫 关注我们
 北京
北京
客服热线:010-83278899
微信公众号 扫一扫 关注我们

项目简介
本发明公开了一种分布式数据库中并发工作负载的性能预测方法,建立线性回归模型,用于判断分布式数据库中查询之间的相互作用,并预测分布式数据库系统中不同并发程度下的查询延时L,数据库通过查询延时L进行任务的选择性分配;其主要步骤包括有:A、查询延时L的度量值选择;B、查询组合并发情况下的相互作用建立线性回归模型;C、实验论证线性回归模型的正确性和有效性。通过反复实验证明查询延时,网络延时和I/O块读次数总的平均相对误差分别为14%,30%和37%,从实验结果可以看出本发明提出的线性回归模型可以很好的对分布式数据库进行并发工作负责的性能预测,从而便于数据库后续的任务分配,可以缩短查询的平均等待时间。
说明书
技术领域
本发明涉及一种数据库中工作负载的性能预测方法,特别是一种分布式数据库中并发工作负载的性能预测方法。
背景技术
现目前,针对数据库工作负载的性能预测已经有了相关的研究。但是现在研究的数据库仅仅局限于单节点的数据库,也就是说该数据库仅有一台服务器,对于一台服务器其性能如何,主要取决于服务器的磁盘和CPU的利用率。随着研究和工业领域产生的数据量的增长,分布式数据库系统被应用于存储和管理PB级数据,并提供高并行性和可扩展性。分布式数据库中的数据通过分散/收集的模式得到处理。例如,查询可以被一个节点分裂出多个子查询,这些子查询可以通过很多其他的节点并发的执行,然后每个节点的部分结果将返回到这一个节点上并进行组合,得到最终的查询执行结果。因此在分布式数据库中,数据是分割地存储在集群中的多个分布式节点上的,并且这个集群可以通过添加新的节点来很容易的进行扩展。这也就是为什么分布式数据库用来存储和处理大数据的原因之一。通常,分布式数据库用来支持并发执行分析型工作负载,以降低需要的查询执行时间。然而,并发执行在带来大量优势的同时也存在着资源竞争方面的挑战,比如判断多个查询之间的相互作用。多个查询之间的相互作用可能是不同的。当两个查询共享一个表扫描时,相互之间可能是积极作用。相反,当两个查询都需要高的网络传输带宽时,相互就会因为网络延时而增加查询执行时间。对于单节点数据库而言,其任务的分配仅仅局限于一台服务器,但是对于多节点的分布式数据库而言,其任务的分配则有多种选择,如何通过任务分配,以实现查询平均等待时间更短,是数据库在进行任务分配时应该考虑的。比如,分布式数据库中存在3个服务器,且都在执行查询任务,1号服务器磁盘、CPU利用率比较低;2号和3号服务器磁盘和CPU利用率比较高,如果此时来了1个查询,将其分配给哪个服务器就需要进行考量了。如果1号服务器还有其它查询在等待或者下一时刻其磁盘、CPU利用率升高,而2、3号服务器下一时刻磁盘、CPU降低时,那么进行任务分配时,就应该考虑将任务分配给2货3号服务器,而不是分配给1号服务器了。因此,就需要对分布式数据库中的工作负载进行性能预测,从而便于后续的任务分配。由于分布式数据库的特殊性,以前的数据库性能预测方法已经不适用于现在的分布式数据库了,而且现有的性能预测方法中并没有针对并发的工作负载进行性能预测。
发明内容
本发明的目的在于,提供一种分布式数据库中并发工作负载的性能预测方法。本发明能够对分布式数据库中并发工作负载进行很好的性能预测,从而便于后续的任务分配,从而缩短查询的平均等待时间。本发明的技术方案:一种分布式数据库中并发工作负载的性能预测方法,通过建立多元线性回归模型,用于判断分布式数据库中查询之间的相互作用,并预测分布式数据库系统中不同并发程度下的查询延时L,数据库通过查询延时L进行任务的选择性分配;其主要步骤包括有:A、查询延时L的度量值选择;B、查询组合并发情况下的相互作用建立多元线性回归模型;C、实验论证多元线性回归模型的正确性和有效性。前述的分布式数据库中并发工作负载的性能预测方法中,步骤A中的查询延时L包括有网络延时和本地处理。前述的分布式数据库中并发工作负载的性能预测方法中,所述网络延时采用网络传输量N作为其度量值;所述本地处理采用I/O块读次数B作为其度量值。前述的分布式数据库中并发工作负载的性能预测方法中,所述步骤B由下列几个部分构成:B1:预测查询相互作用;B2:预测查询延时;B3:基于抽样的线性回归模型训练。前述的分布式数据库中并发工作负载的性能预测方法中,所述B1步骤包括有:主查询q在与副查询p1...pn并发执行的情况下的I/O块读次数B以及网络传输量N的预测;其中I/O块读次数B通过下列线性回归模型预测:网络传输量N,,下列线性回归模型预测:所述步骤B2通过下列线性回归模型对查询延时L进行预测:L=Cq+β1*Bq+β2*Nq(3);所述步骤B3为:通过给出2个以上的查询,并使用LHS生成不同查询组合,并成对的运行不同的查询组合,记录下每个查询组合时的I/O块读次数和网络传输量来组成样本,使用样本通过最小二乘法估算出线性回归模型的系数β1、β2、β3和β4;式中,Bq为主查询q的I/O块读次数;为所有副查询的I/O块读次数之和;
为所有副查询对主查询的直接影响值的I/O块读次数之和;
为所有副查询之间的间接影响值的I/O块读次数之和;Nq为主查询q的网络传输量;
为所有副查询的网络传输量之和;
为所有副查询对主查询的直接影响值的网络传输量之和;
为所有副查询之间的间接影响值的网络传输量之和;Cq为查询q的CPU开销时间。前述的分布式数据库中并发工作负载的性能预测方法中,所述步骤C为:在多元线性回归模型中运行查询Q1、Q2、Q3……Qn得到测量值,然后将测量值放入多元线性回归模型中输出,得到预测值,预测值一部分抽样分为测试数据集,另一部分分为训练数据集,并观察预测值与测量值之间的拟合情况。前述的分布式数据库中并发工作负载的性能预测方法中,所述网络传输量采用节点之间的网络传输包数作为衡量查询执行时的原始数据。前述的分布式数据库中并发工作负载的性能预测方法中,所述网络传输包数和I/O块读次数使用SystemTap进行获取。本发明的有益效果:与现有技术相比,在分布式数据库中由于节点之间数据的传输,系统中执行查询时会涉及到网络开销,因此在预测并发查询执行性能的时候,考虑了网络延时,本发明中提出了线性回归模型来预测分布式数据库系统中并发执行分析型工作负载时的交互作用。由于网络延时和本地处理是查询执行时间最重要的两个因素,因此在本发明中,本发明从网络延时,本地处理以及不同程度的并发性三个方面,利用线性回归模型来分析查询执行行为。另外,本发明中采用抽样技术来获得不同并发程度下的查询组合。本发明的模型是在由PostgreSQL构建的集群中,利用典型的分析型工作负载TPC-H数据集来完成性能预测,通过反复实验证明查询延时,网络延时和I/O块读次数总的平均相对误差分别为14%,30%和37%,从实验结果可以看出本发明提出的线性回归模型可以很好的对分布式数据库进行并发工作负责的性能预测,从而便于数据库后续的任务分配,可以缩短查询的平均等待时间。
附图说明
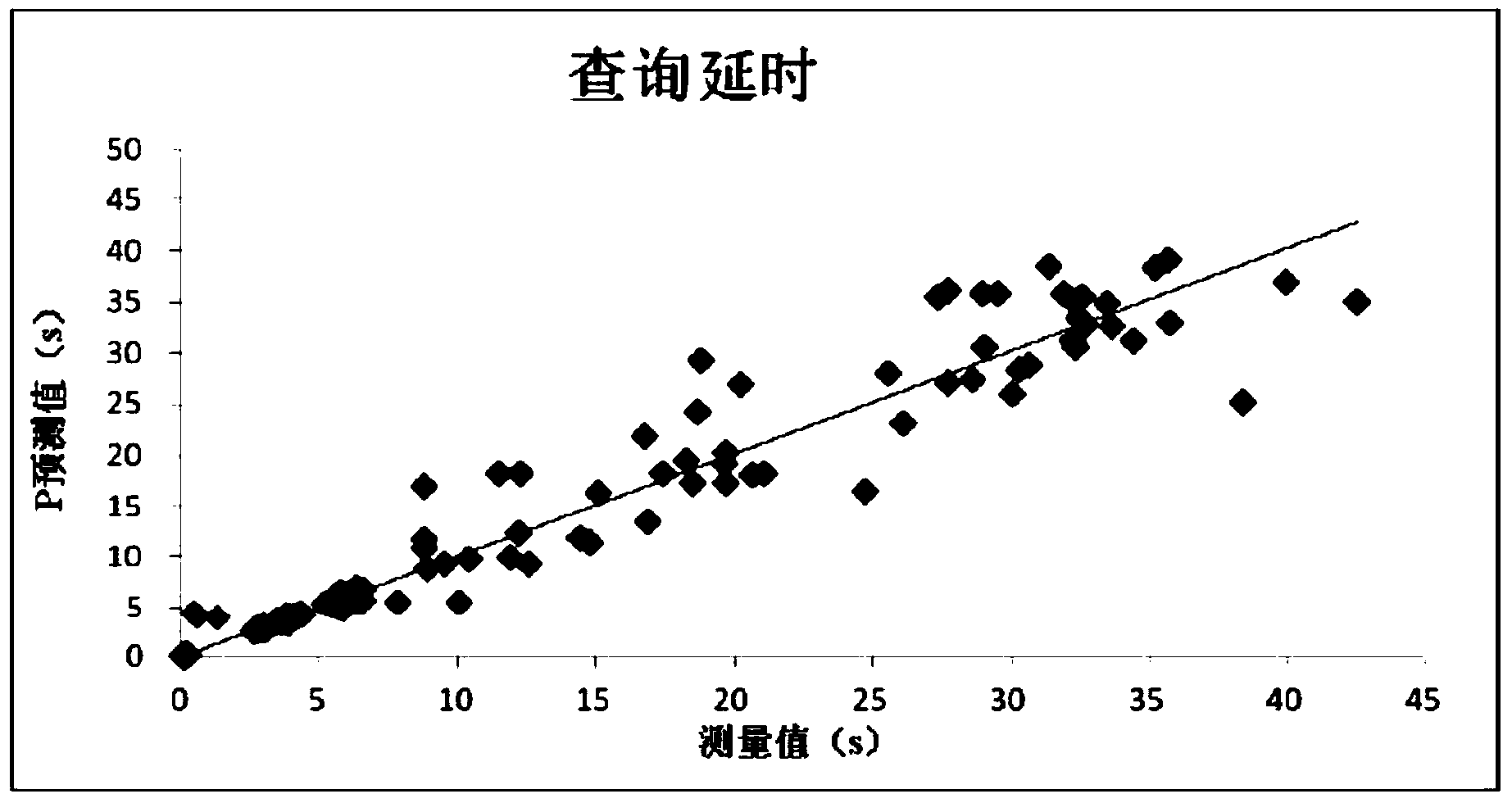
附图1为本发明的查询延时的预测值与测量值的拟合示意图;附图2为本发明的I/O块读次数的预测值与测量值的拟合示意图;附图3为本发明的网络延时的预测值与测量值的拟合示意图;附图4为本发明在并发程度为3时的平均相对误差示意图;附图5为本发明在并发程度为4时的平均相对误差示意图;
具体实施方式
下面结合附图和实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。本发明的实施例:1.性能预测本发明的目标是研究分布式数据库系统中的并发查询延时性能预测。分布式数据库系统中的性能主要受共享基础资源情况下的资源竞争影响,共享的资源有RAM,CPU,磁盘I/O,网络带宽等等。因此在本发明中,首先选择可以用于并发工作负载下查询延时性能预测的有效度量值,特别是针对分布式数据库系统。本发明着重预测分布式分析型工作负载的并发查询延时。分布式数据库系统中的分析型查询主要涉及网络延时和本地处理两个方面。本地处理是用于检索和处理一个查询从节点上获取得到其需要的数据。本地处理时间是当在节点上检索数据的请求提交到需要的块得到返回之间的时间平均值。对于逻辑I/O请求,本地处理需要很多次的磁盘检索,一系列的连续读和少量的写,或者缓存以及缓存池的访问。通常,本地处理时间大部分用于I/O操作,另外读操作远远多于写操作。因此在本发明中,采用平均I/O块读次数作为衡量本地处理维度上进行查询延时性能预测的度量值。由于分布式数据库中的数据是通过分散/收集的模式进行处理,因此执行查询时的网络传输是必要的。数据被分割并存储在集群中的多个分布式节点中,传输的数据可能是从本地节点上获得的部分查询结果,或者是把最终结果返回给提交此请求的节点。网络传输量是分布式数据库系统中影响查询延时的因素,因此本发明中使用它作为网络延时维度上的度量值。本发明主要针对于中等复杂分析方面的研究。为此本发明从TPC-H中选取了10条中等复杂查询语句来组成本发明的查询分析组合,这些查询语句着眼于分布式数据库系统的并发执行性能。首先,选取10条查询语句在不同程度的并发情况下,利用TPC-H产生10G的数据集,再由4节点组成的PostgreSQL集群上运行该查询语句获得测量的查询延时时间,其中MPL代表查询执行并发数量,体现并发程度。如表1,本发明可以看出不是所有的查询语句的延时都会随着并发数的增加而呈现现线性增长的趋势。表1.在不同并发程度下10个查询的平均查询延时2.相互作用建模在前面部分的论述中本发明将分别采用I/O块读次数和网络传输量作为本地处理和网络延时两个维度上的度量值,来预测不同并发程度上不同查询组合的性能。因此在此部分,本发明提出了两个多元线性回归模型来研究查询组合在并发情况下的相互作用。接着本发明又提出一个线性回归模型,并利用I/O块读次数和网络延时来进行查询延时预测。最后利用抽样后的数据集进行训练得到本发明的预测模型。为了预测查询在并发执行情况下的相互影响,首先本发明判断当查询在两个并发情况下执行时的I/O块读次数和网络传输量方面的影响,然后逐渐增加并发度。特别是本发明构建多元线性回归模型来分析在两个并发程度下的相互影响。为了使本发明的模型更加容易理解,本发明把查询分为主查询和副查询。主查询是在并发情况下本发明想研究其被影响情况的查询,副查询是与主查询并发执行的查询。在介绍本发明提出的模型之前,先介绍相关变量。这些变量的值都可以从训练数据集中获得。隔离值:本发明提出此变量作为一个基值,也就是主查询在无并发情况下执行时的值。本发明把此值作为判断并发情况下相应值的一个基值。例如对于查询i,本发明用Bi表示I/O块读次数,用Ni表示网络传输量。并发值:同样的,此变量的值是并发查询的隔离值总和,如上例中的Bi或者Ni。直接影响值:本发明使用此值来表示副查询对主查询的影响,它是变化的度量值的总和。例如当i是主查询,j是副查询,对于网络传输量来说,Ni/j表示直接影响度量值,其变化值是ΔNi/j=Ni/j-Ni。间接影响值:本发明应用此变量来表示副查询直接的相互影响,其值为副查询的直接影响值之和。因此,本发明使用以下公式来预测查询q在与p1...pn并发执行的情况其平均的I/O块读次数B和网络传输量N:本发明将采用最小二乘方法来估算每个查询的系数β1,β2,β3,β4这些系数将从训练数据集中通过训练获得。本发明同时考虑I/O块读次数和网络传输量两个方面来建立线性回归模型预测每个查询的查询延时。一般对于分布式数据库系统来说,查询延时主要由网络延时和本地处理来组成,而本地处理时间主要包括特定的CPU开销时间和平均的逻辑I/O等待时间,因此查询q的查询延时可以通过以下公式进行预测:在上述公式1、2和3中,Cq代表查询q的特定CPU开销时间,Bq表示平均I/O块读次数,Nq表示分布式数据库中多个节点之间的平均网络传输量。本发明将对样本使用最小二乘法进行反复的实验来获得系数β1,β2。为了更加易于理解本发明提出的模型,接下来介绍一个简单的例子。假如本发明想预测在分布式数据库系统中查询a在与查询b,c并发执行情况下的查询延时,本发明首先需要计算以下值:查询a,b,c的隔离I/O块读次数值Ba,Bb和Bc,和隔离网络传输量值:Na,Nb和Nc。与查询b,c并发执行情况下,查询a的直接影响值:△Ba/b,△Na/b,△Ba/c,△Na/c。间接影响值:△Bc/b,△Nc/b,△Bb/c,△Nb/c。本发明可以通过以下两个公式来分别获得相应的度量值。Ba=β1Ba+β2(Bb+Bc)+β3(△Ba/b+△Ba/c)+β4(△Bc/b+△Bb/c)Na=β1Na+β2(Nb+Nc)+β3(△Na/b+△Na/c)+β4(△Nc/b+△Nb/c)接下来将使用公式3来预测查询a的查询延时:La=Ca+β1*Ba+β2*Na为了从前面描述的公式3中获得查询延时,需要训练本发明的预测模型。首先,给出10个查询分别运行时的特征,即为查询执行延时、I/O块读次数以及网络延时,这10个查询是在不同的MPLs下各种查询组合的基线查询语句,当本发明成对的运行查询时,如55个成对查询可以获得他们如何影响对方的具体的特征。为了在多个机器上运行这些查询语句,同时较高程度的交互行为,本发明使用LHS来生成不同查询组合来代表本发明所需要的工作负载。LHS是一个分层抽样函数,它能够很方便的产生样本数据。在表2中,本发明给出来MPL2上的一个LHS例子,在这个例子中能够看到LHS生成了5个成对的查询。在实验中,记录下每个查询的I/O块读取次数和进行每个查询组合时的网络传输量来组成样本,这些样本用来估算模型的系数。对于每个查询,生成了很多查询组合实例来组成样本。比如,查询3表示Q3,Q4,Q5组合,但是Q3是主查询,Q4,Q5则是副查询。表2.2维LHS示例对于所建立的线性回归模型,需要评估提出的三个模型的正确性和有效性。通过实验将分别了解查询延时,网络传输量和I/O块读次数的测量值和预测值情况,并针对并发程度为3和4时,了解每个查询的平均相对错误率。3.实验论证为了评估方法的可行性和模型的准确性,选择在由TPC-H提供的QGEN产生的10G数据集上执行查询。由于本研究侧重于分析性工作负载,因此本发明从TPC-H的22个查询中选取Q3,Q4,Q5,Q6,Q7,Q8,Q10,Q14,Q18,Q19来组成本发明的查询组合。选取这些查询是因为这些查询时间相对较长,可以提供更多的时间,利于本发明收集I/O块读次数和网络传输量。本实验的分布式数据库系统是由四个PostgreSQL节点组成的数据库集群,实验中使用Postgres-XL来实现此功能,Postgres-XL是一个开源的PostgreSQL数据库集群,对处理不同的数据库工作负载都具有高水平伸缩性和灵活性。集群部署在4核,2赫兹处理器,8G内存,型号为Intel(R)Xeon(R)CPUE5-2620的物理机上,每个节点运行的操作系统是内核为Linux2.6.32的Centos6.4。首先通过抽样技术获得训练数据集,并使用Matlab来得到多元线性回归模型,接着使用测试数据集来预测在并发执行下查询的I/O块读次数和网络延时。而训练数据集和测试数据集则通过下列方式获得,在多元线性回归模型中运行查询Q1、Q2、Q3……Qn得到测量值,然后将测量值放入多元线性回归模型中输出,得到预测值,预测值一部分抽样分为测试数据集,另一部分抽样得到训练数据集,并观察预测值与测量值之间的拟合情况。预测值和测量值之间的拟合情况在图1中给出。在实验中,本发明使用决定系数R2来衡量回归模型是否拟合的很好。决定系数R2的取值范围为0到1,其值越是靠近1,说明预测值和测量值越接近,本发明的回归模型就越好。图1,2,3分别说明了在多并发情况下,利用本发明提出的预测模型获得的查询延时、网络延时和I/O块读次数,在预测值与测量值之间的拟合情况。依次R2的值分别为0.94,0.58和0.84,这说明本研究工作中利用网络延时和I/O块读次数来预测查询延时的能力。对于每一个查询,首先使用公式1和2中的模型来预测网络延时和I/O块读次数,最后使用公式3来预测查询延时。在实验中,本发明采用节点之间的网络传输包数作为衡量查询执行时的网络传输量的原始数据。需要值得注意的是获取原始数据的方法,因为这些原始数据经过处理之后成为样本,而影响线性回归模型好坏的两个重要因素分别是样本的质量和数量,因此获取原始数据的方法很重要。为了收集每个查询执行时的I/O块读次数和网络传输量,本研究中使用SystemTap执行编写的脚本来动态获取数据。SystemTap是监控和跟踪运行中的Linux内核的操作的动态方法。为用户提供简单的命令行窗口和脚本语言。与通过捕获PostgreSQL自身的统计数据或者利用其他工具来获得网络延时相比,使用SystemTap更能获取准确的网络传输包和I/O块读次数。另外为了获得更多的时间来获取数据,也为了使得获取的数据更加准确,本发明适当的调整了PostgreSQL的shared_buffer值。如前所述,本发明应用普通最小二乘法(OLS)来获得模型中的系数。根据普通最小二乘法,从经验上来说至少需要6个样本来预测查询延时才能满足基本要求。实验当中,本发明采用了120个样本值,同样为了预测网络延时和I/O块读次数,也至少需要13个样本,本研究中使用了140个样本。实验中也发现,当增加样本数量时,整体的变化趋势也没有发生特别的改变,相反只是使点更加密集而已。在图1中,为了使更多的点展示在图中,因此没有展示值特别大的点,比如查询18的查询执行时间就没有在图1中体现出来。另外,在图3中对于网络延时的预测,本发明可以看到一些预测偏高或者偏低的点。这是由于实验网络的波动或者在收集数据时的包丢失使预测值和观测值的误差较大。此外,为了更接近于实际应用场景,实验中每次执行查询时都没有清除缓存,这也是为什么当增加并发程度的时候预测准确度有稍微降低的原因之一。对比图4和图5中I/O块读次数的平均相对误差并可发现此现象。对比图4和图5还可以发现,查询3(Q3)在并发度为3时的平均相对误差高于并发度为4时。通过分析可以得知,这是因为查询3(Q3)的执行时间过短以至于不能更准确的获取源数据,样本质量过低使预测误差偏高。图4、图5分别展示了在并发程度为3、4时,查询延时,网络延时和I/O块读次数的平均相对误差,其中平均相对误差通过|(测量值-预测值)/测量值|计算所得。查询延时,网络延时和I/O块读次数总的平均相对误差分别为14%,30%和37%。该实验结果表明使用本发明提出的模型可以很好的对分布式数据库系统进行并发工作负载的性能预测。

企业营业执照
专利注册证原件
身份证
个体户营业执照
身份证
专利注册证原件
专利代理委托书
转让申请书
转让协议
手续合格通知书
专利证书
专利利登记簿副本





提交

公众号
全国技术转移公共服务平台